
Clear in the iCloud
There has been a lot of talk about iCloud + CoreData (referred to as iCCD hereafter) over the past few months and I think it is a good time for me to share our journey in getting iCloud integrated in Clear. If you do not want to read through all the details: Clear uses a custom system built on top of iCloud File Storage and it works in a similar fashion to Operational Transformation. The post proceeds to cover the reasons for choosing iCloud, then explores iCCD and subsequently builds a synchronisation system from the ground up.

Sync
Let us start from the very beginning — iCloud was one of the most requested features even before Clear for Mac was announced. There would have been no point in releasing the Mac app if it could not sync with the iPhone app. The first and most obvious question was – do we use iCloud, roll our own system or use a third party? In order to make an informed decision, we had to carefully evaluate both the technical and non-technical aspects of each alternative. In the end, we decided to go with iCloud simply because it is built into every Mac and iOS device, making it extremely easy to use – no registration is required, we just have a single button to turn it on. Furthermore, Apple has been heavily pushing iCloud and as good platform citizens, we ought to support iCloud. Thus iCloud was the chosen one.
If you have dealt with sync, you must be aware that it is a very hard problem to solve. The general problem is not even well-defined because the meaning of the word sync is so domain dependent – individual sync solutions might be considered both adequate and completely unsuitable depending on the use case. After having decided to use iCloud, as with any new non-trivial technology, we had to perform an extensive evaluation and determine whether it could satisfy our requirements. It is not a wise idea to commit to using brand new technologies without a proper evaluation, especially when such technologies are providing “just works” solutions to hard problems – a good rule of thumb is to have an in-depth knowledge of important systems that you are utilising and be aware of their inherent trade-offs so that you can make informed decisions (the devil is in the details).
CoreData
Since we were already using CoreData for persistence, it was natural to consider iCCD. As it should be of no surprise at this point, the implementation aspect of iCCD makes it unusable in production systems, at present. The problems have been widely documented, so I will not repeat them here. While the implementation bugs will be fixed eventually, the more interesting aspect of iCCD is the abstraction and approach that it uses. At its core, iCCD synchronises object graphs by replaying sets of changes made by each participating device. This strategy has a very interesting property – the composition of sets of changes does not guarantee a consistent object graph, even if each set of changes resulted in a locally consistent graph. Fundamentally, the object graph is distributed with no central components which guarantees global consistency. Any inconsistency might either be at the CoreData level or at the application level. For example, let us suppose that we have an object A on devices 1 and 2 and that both 1 and 2 go offline. Then, device 1 deletes object A while device 2 adds a child of object A, namely object B, and B requires to always have a parent (e.g., a file always must be contained in a folder). After some time, devices 1 and 2 go online. The problem arises from the fact that device 2 added an object as a child of a globally non-existent object – it just could not have known about it at the time.
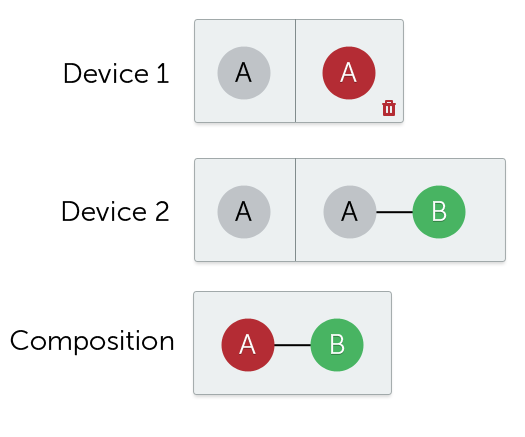
How do you resolve such situations? You can either just lose object B or you can resurrect object A. Bear in mind that this is a very simple contrived example and much more complex edge cases will be encountered in production – imagine having large object graphs that need to be resurrected, which might not always be possible, due to domain specific rules. As it currently stands, no mechanism exists to run custom code in such situations to provide conflict resolution – whatever behaviour the engineers of iCCD implement, it will be always be incorrect for someone because conflict resolution is domain dependent (ideally, there will be API hooks which can be used to specify a custom behaviour which overrides a sane default). This is the price you pay of “just works” – while it makes it super easy to get up and running, you might be in trouble once you start hitting those edge cases. I want to stress the fact that if you are about to use a particular technology, evaluate its performance in your use-case, do not rely on Internet anecdotes.
So we ruled out iCCD for use in production due to both implementation and abstraction issues, which left us with building our own system on top of iCloud File Storage (at the time of writing, iCloud still suffered from rare bugs when it comes to synchronising files).
A desirable property of a sync system would be to have the flexibility to define the behaviour when the object graph is accessed concurrently.
Abstraction
As it stands today, iCloud provides the communication layer (via files) in a peer to peer architecture where all participating devices are equal. While there is a central iCloud server component, the communication can still be thought of as peer to peer because the server-side does not actively participate in the synchronisation process, it mainly provides the communication medium and stores the data (sidenote: iCloud devices on the same local network can exchange information directly which speeds up the transfer of large files). Developers cannot provide code to be run on the central servers, only on the iOS / Mac OS X devices. This has an important implication – developer code can only ever have a local view, not a global view. Furthermore, any synchronisation system based on iCloud (as of iOS 6 / OS X 10.8) must use algorithms designed to work in a peer-to-peer environment, as no device is inherently a master or has a global view. For example, when you are deleting an object, you cannot know whether there will be orphaned children – some other peer might have created children of the object that you deleted but it might not have synced yet. It follows that you cannot guarantee that the composition of actions from multiple peers would result in a consistent object graph, where consistent has a domain dependent definition.
Thus a sync system should be able to guarantee consistency which would be domain dependent.

Information Loss
Let us take a step back and talk about information loss. In software, you have layers of abstractions which are implemented of top of other abstractions. Most of the time, the mapping between the abstractions is such that there is no information loss or the information being lost is not practically relevant. But in the case of synchronisation of object graphs, you might be losing important information. The key to keep in mind is that you are translating user actions into sets of operations on an object graph – if that graph distributed, problems can arise in certain situations. In Clear, when you complete a task, it moves to the top of the completed tasks. You might have realised that the position “top of completed tasks” is defined relative to the current global state. But the device making the change does not have a global view, only a local view. What if another device had completed a task (but not yet synced) before the device in question completed the task? Its position would have to be revised in light of the new information when the devices sync next. But the chances are that your backend model cannot express the semantics of “move at the top of completed tasks at time X”. Instead, it will probably map the user action to “move task Y to position Z” and you have suddenly lost information when your object graph becomes distributed. This is why you want to keep as much information as possible, conveying the meaning of the user action at the highest possible level, as opposed to what that the user action was serialised to at the abstraction level of the underlying persistence layer. It is also not possible to fully simulate the completed task behaviour by just sorting the completed tasks by their completion time in descending order (assuming synchronised clocks). In Clear, the user is also allowed to re-order these tasks. While we could have restricted the movement of completed tasks in the app, that is not a good approach – we do not want to be bending the app’s behaviour just to make it easy to implement. It is our job, as developers, to find ways to implement behaviour the way it was specified.
In summary, a sync system must be able to correctly represent user actions without any information loss.
History
We have just seen that the inability to correctly represent the semantics of user actions can result in the loss of important information. Third party sync systems are available today that allow you to store objects in the cloud. Depending on the particular implementation of such a system, it might exhibit consistency and history issues. When a client makes changes and synchronises them, there is usually no guarantee that the object graph stays consistent. This stems from the fact that the changes might be applied to a different state than the one which they were generated against (any client always has a local view at a particular time point).
Furthermore, it might be important to keep a history of changes – the object graph is indeed defined by the sets of modification that each peer makes. Fundamentally, a synchronisation system needs to be able to revise the history when it is provided with new information. For example, imagine that multiple clients modified the same field of an object. By keeping the history, you might have to revise the current state to pick the latest value when a new change becomes available. While you can provide the same functionality by keeping a timestamp for each field (storing the last modification date; requires synchronised clocks), this approach has limited expressive power and does not work in the general case (it implements a conflict resolution scheme of “pick latest value, in chronological order”).
Following from the above, it would be desirable for a sync system to keep the history of changes.

Architecture
Thus far, we have laid out the rationale for requiring the following properties of a sync system:
- Ability to define behaviour under concurrent object graph access.
- The guarantee of domain specified consistency.
- Exact representation of user actions without information loss.
- Storage of change history.
We can satisfy those properties by building our sync system using the following approach – each device broadcasts the changes that it is making to everyone else. Each “change” is as high-level as possible description of the action on the abstract data model – for example, we have changes for “create list”, “change title of list”, “delete task”, etc. This approach preserves as much information as possible – it can be thought of as an append-only system composed of abstract model changes. By carefully defining the semantics of all changes such that they obey “if a change is a applied to a consistent object graph, then the resulting object graph is also consistent”, we can guarantee that any set of changes always produces a consistent object graph (by structural induction).

Time
Now that we have our abstract system, how do we actually derive an object graph out of those set of changes? All we need to do is replay them in the correct order. When a user performs an action, a change is generated against the current state of the data model. That data model is itself generated by replaying another set of changes, thus the correct order for a particular change is to be applied after all changes that were used to generate the data model that it was generated against. We can define a relation happened-before between two changes, s.t. A happened-before B iff B was generated against a data model containing change A (note that iff is an abbreviation for the if and only if logical connective). This relation forms a partial order only – we can have pairs of changes, s.t. neither of them are related to each other, i.e., neither occurred before the other. We call those pairs of changes concurrent. The correct order for changes that are related by happened-before is obvious – if A happened-before B, replay A and then B. For concurrent changes C and D, there is no inherent order as neither of them happened before the other, by definition. But we need a total order to be able to construct an object graph, thus we have to choose an arbitrary order – in the case of Clear, concurrent changes are ordered by their timestamp, providing a good enough guess at ordering them correctly.

How do we actually implement the happened-before relation? Leslie Lamport thought of a way to do exactly that 35 years ago, which is the algorithm Clear uses (with a slight modification). The idea is quite simple: each change gets assigned a logical timestamp which is greater than all the timestamps of the changes used to generate the object graph (against which the change is created). By using this algorithm, the following holds: if A happened-before B, then timestamp(A) < timestamp(B). Note that this is a logical implication, thus it holds only one way. The contrapositive tells us: if timestamp(A) ≥ timestamp(B) then ¬ (A happened-before B), and if we simplify, we get: if timestamp(B) ≤ timestamp(A) then (B happened-before A) ∨ (A concurrent with B). Thus we can get a correct order by replaying changes sorted by their timestamps: a change will be replayed before another if and only if it happened before it or if the changes were concurrent.
Determinism
There is another very important property of the system – it needs to be deterministic. In our case this means that whenever any two devices see the same set of changes, they must construct the same object graph (otherwise, calling it “syncing” would be inaccurate). You might have noticed that we have not quite defined a strict total order, which is a requirement to make graph construction deterministic. We need to handle the case of ordering two changes which have the same timestamp (those must originate from different devices as changes from the same device are always strictly ordered). In Clear, changes are further sorted by the device UID (since those UIDs are probabilistically globally unique, this means the order is well-defined).
Consistency
It is theoretically possible to get inconsistent cuts by ordering changes by their Lamport timestamps. An inconsistent cut is a set of changes, s.t., there exists a change which belongs to the set even though it depends on another change which does not belong to the set. To illustrate, imagine C1 is “create-list-with-id-X” generated by device A and C2 is “delete-list-with-id-X” generated by device B. In theory, there is no guarantee that we will see C1 whenever we see C2 (the logical implication does not hold: see(C2) → see(C1)). That is not a problem in our case because the semantics of such changes are defined as nop. In the general case, an inconsistent cut cannot be detected by only looking at the logical clock timestamps because they do not carry sufficient information. If stronger consistency is required, there are more sophisticated algorithms, in particular: vector clocks, matrix clocks and interval tree clocks. Any partial order that is produced by those schemes can be turned into a total order by transforming it into a DAG and applying a topological sort.

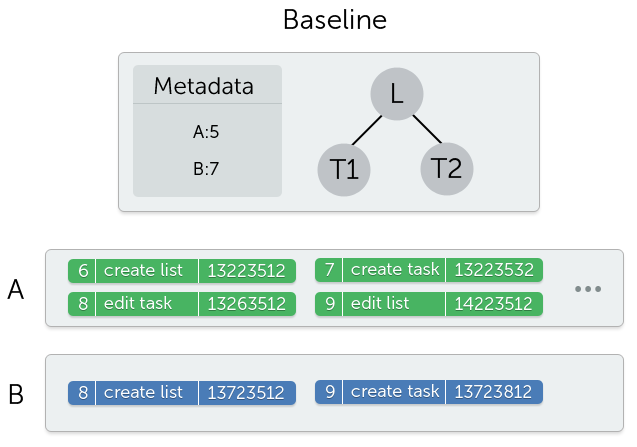
Storage
Currently, our sync system suffers from an infinite increase of storage due to its append-only design. This can be resolved by baselining – you compact immutable history to only record its net effect. For example, imagine that at some point in the past, a task was created and subsequently deleted. All changes relating to that task do not need to be stored anymore (iff the whole history up to and including the point of deletion is garbage collected). Thus, devices need to periodically re-baseline history to reclaim storage space. There are two important aspects of the baselining process: immutability and conflict resolution. Since we are dealing with a distributed system where devices are disconnected from each other, it is entirely possible that two devices concurrently compact the history. We need to have a way to resolve such conflicts which iCloud exposes – developers can access the contents of all unresolved conflicting versions. Each baseline can be thought of as containing a set of changes and we can define a subset relation on baselines as follows: baseline A ⊆ baseline B iff set of changes in A ⊆ set of the changes in B. Conflict resolution for a pair of baselines A and B is performed the following way: if one of the baselines is a subset of the other, pick the superset baseline; otherwise, compute the union data model from the two baselines. This conflict resolution is conservative in nature, i.e., data is never lost. In practice, baselines will almost never be disjoint as it only happens when a device is offline for a very long period of time. That is due to the immutability aspect – devices only ever baseline probabilistically immutable histories. The above implies that for any two immutable histories, they would either be equal or one would be a superset of the other. Each immutable history can be thought of as “including all changes from all devices up to timestamp X”, thus if another devices computes the immutable history up to timestamp Y, either X < Y, Y < X or X = Y and it is easy to see that we can derive the subset relation for any such pair of immutable histories.

Before we go any further, we need to define how we check for the subset relation. When a device joins iCloud, it gets assigned a unique ID (that happens each time iCloud gets enabled, so the same physical device will get different UIDs each time it enables iCloud). Each such unique ID can be thought of a single timeline and iCloud contains one timeline per active device. Timeline changes are sequentially numbered giving us an easy way to express a set of changes from a particular timeline: A:6 represents the set of changes from timeline A up to and including change 6. A baseline’s metadata contains a set of such representations: e.g., A:6, B:3, C:7 allowing us to quickly compute if any particular baseline is a subset of another. Note that if we just stored a timestamp X, we cannot tell what changes are included thus making it impossible to check for the subset relation.
In order for a peer to create a baseline, it needs to pick the set of changes that will be compacted. This is done by computing a cut-off point (i.e., logical timestamp) and including all changes up to and including that timestamp. The immutable history cut-off point is calculated by the following algorithm: for each device timeline, pick the change with the highest sequence ID, such that there are not gaps starting from the baseline (or 0 if no baseline exists) up until that sequence ID.
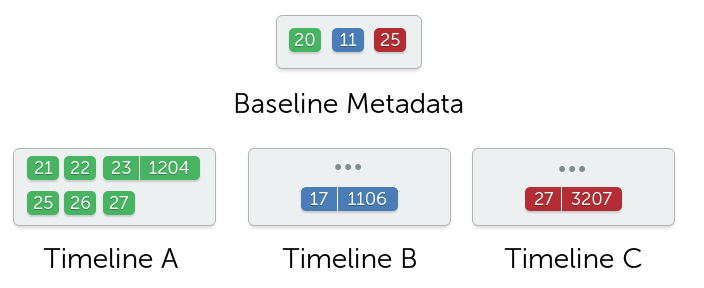
For example, if the current device can see changes A:[21-23], A:[25-29] and a baseline including changes up to A:20, then the sequence ID for timeline A would be 23. The cut-off point is the minimum timestamp of each timeline sequence ID computed above. To illustrate, assume we have computed the following maximum continuous sequence points: A:23, B:17 and C:27. Each of these sequence points has an associated logical timestamp, for example: A:23 = 1204, B:17 = 1106, C:27 = 3207. The cut-off point would be MIN(1204, 1106, 3207), i.e., 1106. The immutable history then includes all changes with a timestamp that is less than or equal to 1106 (see note at the bottom about the probabilistic nature of this assertion). It is trivial to see why those sets of changes are immutable – any change created by either A, B or C would have a timestamp greater than 1106, i.e., it will be ordered after all changes included in the baseline, thus it cannot have an effect on the object graph derived from the changes up to 1106 (inclusive).
System Properties
A peculiar property of the system is that the actual object graph is never stored on iCloud, only instructions on how to build it. When new data arrives from other devices, the whole history needs to be reconstructed to be able to obtain the latest object graph. Since that would be terribly inefficient, Clear keeps a cached local copy of the object graph, assuming that anything older than 2 days probably will not change. Since each cached copy contains metadata about the changes it is constructed from, it can be easily checked whether it is invalid – in this case, Clear invalidates the cache and replays more history. In practice, the cached is almost never invalidated.
A neat aspect of the design is that we can re-use the same set of changes to actually talk to our local storage layer – this is exactly how Clear works. So when a user edits a task, “edited task X with text Y” is generated and is sent to the local storage engine and if iCloud is enabled, to the remote one as well.
With regards to backwards and forwards compatibility, each change has a version number and Clear can detect unknown change types and version numbers. Consequently, at any point in the future, we can add types of changes or modify existing ones – old versions of the app will inform the user to update as it will detect changes from a future version. On the other hand, the old version can still be used as it will be generating types of changes that later versions can handle but it will not be able to get updates generated by those later versions. The baseline is also versioned.
Due to the way the semantics of creation changes are defined, Clear seamlessly handles a peer joining and leaving multiple times without creating copies of the same data. When a device joins iCloud, it pushes its current object graph as a set of changes (so it would push create changes for each entity). When a device replays creation changes, it can detect duplicate requests for the creation of the same object (by looking at the object UID).

Probability
It should be noted that the system described above is probabilistic, stemming from the distributed nature of iCloud – a peer only ever has a local snapshot of the global state. For example, a device cannot know whether there is some other device that has not synced yet or whether a device has gone offline forever. Consequently, all algorithms employed must be designed to take these scenarios into account. In Clear, the system handles any such cases by simply never losing data – i.e., taking a union defined on the object graph. In very rare cases, it might end up with the undesirable behaviour of a deleted object re-appearing but that is preferable to losing data.
There are many other intricacies in the system but the above description provides a thorough architectural overview which should be sufficient for anyone to implement a similar synchronisation scheme. If you have any questions, feedback or you found errors, feel free to contact me over email or Twitter.
 You should follow @milend for more.
You should follow @milend for more.